
微观主体外汇违规行为监测预警研究
【内容摘要】党的二十大报告提出,加强和完善现代金融监管,强化金融稳定保障体系,依法将各类金融活动全部纳入监管,守住不发生系统性风险底线,这为外汇管理工作指明了方向。本文利用2018年至2021年广东省微观企业外汇数据,基于逻辑回归、随机森林、极端梯度提升树、改进的梯度提升树和支持向量机等模型,引入采样方法及集成学习技术,对外汇违规主体样本进行拟合并开展预测分析。研究发现:一是通过叠加使用采样算法和平衡装袋分类器等集成算法可有效强化预测效果。二是在多种机器学习技术中,极端梯度提升树、改进的梯度提升树、随机森林三项模型可实现较佳预测效果,整体准确率保持在80%以上。三是搭建模型可实现对外汇领域微观主体监测的稳定预警效果。基于实证结果,本文从数据、模型、监管和安全四个维度出发,提出了基于大数据及机器学习技术的“四位一体”外汇微观监管政策框架及措施。
【关键词】微观监管 外汇违规 机器学习 大数据
一、引言
微观主体外汇违法违规行为加大了外汇领域风险,给外汇管理和跨境资金流动风险防范带来了挑战。为有效管理微观主体外汇违法违规行为带来的风险,需要健全微观主体外汇违法违规行为监测预警机制,完善微观主体行为监测框架,丰富微观主体行为监管的政策工具箱。传统的微观主体行为监测多基于外汇管理系统数据,采用统计学和计量经济学框架,监测效果受限于非现场监管人员的经验和能力,存在效率不高、前瞻性不足等问题。本文在梳理现有大数据和机器学习技术的基础上,运用微观主体大数据建立和优化微观主体行为监测预警大数据模型,对微观主体行为进行监测分析,在此基础上提出基于大数据技术的外汇领域微观主体行为监管政策框架及具体举措。
二、文献综述
近年来,大数据技术在金融领域的研究取得显著进展。翟伟丽(2014)阐述了金融体系在大数据时代的重构问题,指出由于参与者的行为得到了充分记录,信用评价和征信体系变得更加有效,大数据的预测能力也将改变风险管理和决策模式。Paolo(2018)描述了金融数据科学的概念,并提出数据科学模型可以在金融科技发展进程中发挥重要作用。阮健弘(2022)认为大数据技术应用让金融统计分析变得更实、更全、更快和更准,为分析经济金融运行、预调和微调货币政策、前瞻识别金融风险等提供了有力支撑。此外,在处理大数据过程中,机器学习得到广泛应用。机器学习方法在处理复杂数据、构建高精度模型方面具有显著优势,可以充分挖掘数据中的非线性、非平稳信息,有效提高经济分析结果的精度(蒋锋等,2022)。
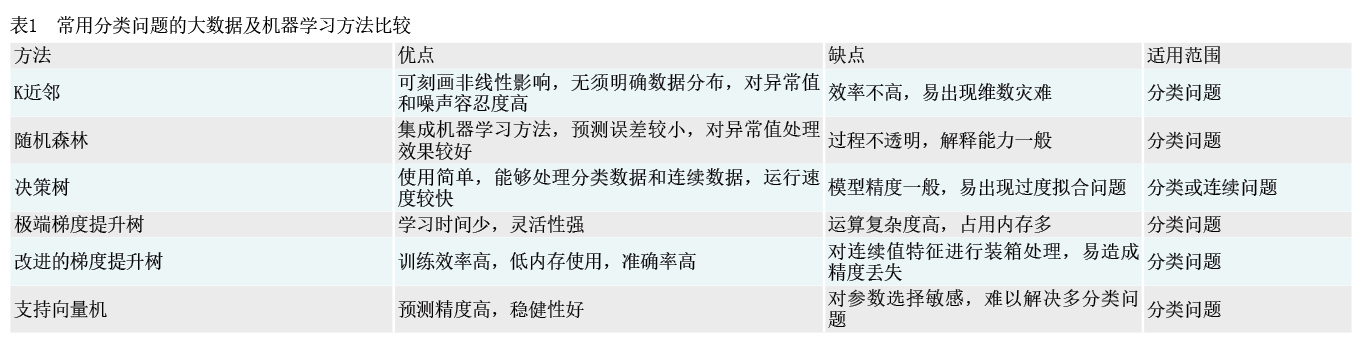
目前,常用的大数据和机器学习技术主要有逻辑回归(Logistic Regression)、随机森林(Random Forest)、极端梯度提升树(XGBoost)、改进的梯度提升树(LGBM)、K近邻(KNN)、支持向量机(SVM)等(见表1),这些方法在金融领域也有广泛应用。王达和周映雪(2020)以韩国等16个国家的宏观经济数据作为训练集,以中美两国的数据作为测试集,对随机森林模型在系统性风险识别中的应用进行了探索式研究,发现随机森林模型对训练集数据学习后不仅通过了稳健性检验,而且具有优异的泛化性能,能够很好地识别中美两国的系统性风险。Suss和Treitel(2019)利用K近邻、随机森林、支持向量机、提升学习(Boosting)等机器学习技术对银行风险进行评估,建立了英国银行危机预警系统,并与逻辑回归等传统统计技术进行比较,发现机器学习技术明显优于传统统计技术,其中随机森林在银行危机预警方面的表现尤其出色。Samitas等(2020)运用决策树、判别分析、支持向量机、K近邻、集成分类器等机器学习模型选取股票指数、主权债券和信用违约互换等数据,对系统性风险进行预警分析,发现支持向量机的预测效果最好,正确率达到了98.8%。
尽管大数据和机器学习技术取得了快速发展,但从现有文献看,其在外汇领域的应用特别是在外汇领域微观主体行为监管方面的应用还较少。对此,本文运用大数据和机器学习技术充分挖掘外汇系统数据,完善外汇领域微观主体行为监测预警,增强外汇微观监管能力,提升外汇管理效能。
三、实证思路、指标及数据
(一)实证思路
第一步,基于现有外汇系统数据及外部数据,构建外汇领域微观主体行为指标体系。第二步,构建基础模型库,加入逻辑回归、随机森林、极端梯度提升树、改进的梯度提升树、支持向量机等模型,利用模型库对数据进行拟合分析。第三步,为解决样本不平衡问题,引入过采样(SMOTE)1、随机过采样等采样算法以及平衡装袋分类器等集成算法,提升模型的预测效果。第四步,使用K折交叉验证(K-Fold)和样本外检验等方法开展稳健性检验。第五步,输出监测预警结果,为外汇微观监管实践提供参考。
(二)指标体系
外汇领域微观主体行为与其自身属性及外汇业务行为密切相关。本文从外汇违规情况、结/购汇金额和频率、进出口金额、外债签约额和提款额、涉外收支情况、特定地区交易、特定交易对手、特定金额业务等方面选取30个指标,构建外汇领域微观主体行为指标体系。
(三)数据来源及处理
本文选取2018—2021年广东省企业外汇业务相关数据进行实证研究。变量相关性热量图显示,各个变量之间的相关性较低。为避免数据量纲对模型拟合结果造成影响,文章对变量采取数据归一化处理,将所有数据压缩在[0,1]区间内。
四、实证分析
本文基于逻辑回归、随机森林、极端梯度提升树、改进的梯度提升树、支持向量机等模型,将2018—2020年数据样本按照70%和30%的比例进行随机切割,其中70%为训练样本,30%为测试样本,并将2021年数据预留用于样本外检验。针对训练模型,参考混淆矩阵(见表2),选用准确率、召回率、真阳性率、假阳性率和AUC2 作为评价指标。

其中,准确率(Accuracy Rate)是指模型正确分类的样本数与样本总数之比,该比率主要说明训练所得模型运用于测试数据时,整体正确识别的概率。公式为:
准确率 = (TP + TN) / (TP + FP + TN + FN)
召回率(Recall Rate)是指模型正确分类数与实际该类分类数之比,主要说明训练所得模型运用于测试数据时,该类数据中有多少可被模型正确预测。其中,负面样本召回率是指负面样本出现时,模型可以正确预测的概率;正面样本召回率即真阳性率(True Positive Rate,以下简称TPR),是指正面样本出现时,模型可以正确预测的概率,TPR越大,代表越多正面样本被模型正确预测。公式为:
负面样本召回率 = TN / (TN + FP)
正面样本召回率 = TPR = TP / (TP + FN)
假阳性率(False Positive Rate,以下简称FPR)是指负面样本出现时,模型将其误判为正面样本的概率,FPR越大,代表越多负面样本被误判。公式为:
FPR = FP / (FP + TN)
最理想的状态下,TPR应为1,FPR应为0,代表正面样本均被正确预测,且无负面样本被错误预测。但大多数情况下,TPR与FPR相互制约,随着越多样本被判断为正面,样本被误判为正面的概率亦同步上升。
(一)全样本分析
首先,基于全样本进行数据训练集及测试集随机切割。然后,基于数据进行训练,逻辑回归所得准确率为50.20%,预测结果接近随机。随机森林、极端梯度提升树、改进的梯度提升树、支持向量机等模型预测的准确率在99%以上,而负面样本召回率均接近0,真阳性率、假阳性率均接近100%,平均AUC为0.60,这说明所有违规主体未能被模型正确识别出违规,其主要原因在于全样本数据的不平衡问题,即正面样本与负面样本数量差异较大3 。实务中,海量企业主体活跃于市场并积极参与外汇业务活动,相较于庞大的企业正面样本数量,因外汇违法违规行为被处罚及曾受关注的企业负面样本数量较小,从而使正面样本与负面样本比例达到10000:3,导致模型对违规样本特征的刻画不足,模型预测违规样本的能力偏弱。
(二)采样算法
为解决这一问题,本文引入采样算法4,运用过采样和欠采样等技术手段进行数据处理,并运用处理后的样本重新进行预测分析。
1. 过采样分析
使用过采样方法,按照1000:1比例,以正面数量为基准,针对负面样本进行过采样计算,人工合成负面样本数据,以解决样本不平衡问题。
经重新组合训练样本并进行训练后,得到结果如表3所示。一是模型整体AUC有一定提高,平均AUC自0.60提升至0.68,提升幅度超13%。二是随机森林、极端梯度提升树、改进的梯度提升树、支持向量机模型在准确率和正面样本召回率未出现明显下滑的情况下,负面样本召回率有所提高,平均AUC呈现上升,说明更多负面样本可被预测识别出,同时假阳性率有所下降,说明被错误归类为正面样本的负面样本数减少。
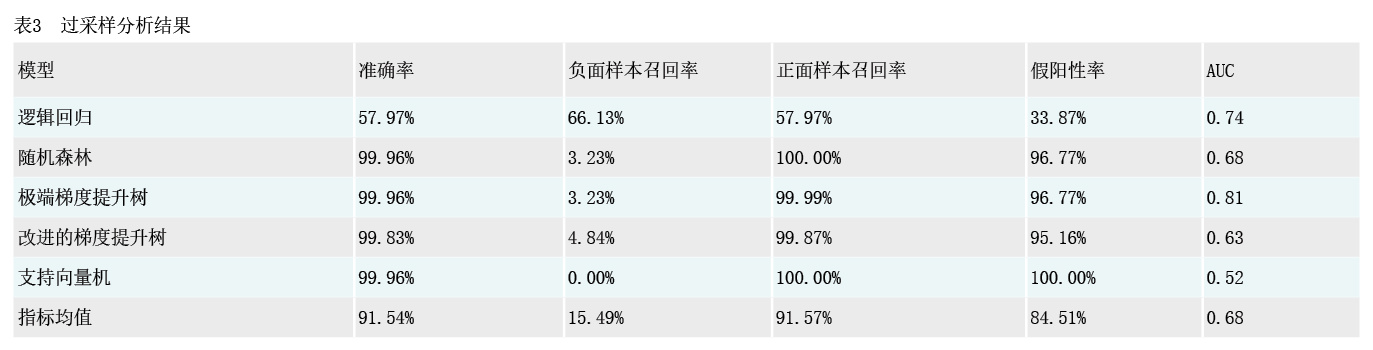
具体就每个模型而言:一是逻辑回归模型负面样本成功召回66.13%,假阳性率为33.87%,整体模型准确率为57.97%,说明虽然负面样本能召回较多,但以牺牲了较大准确率为代价,模型性能整体不够均衡。二是随机森林、极端梯度提升树、改进的梯度提升树模型在对总体样本预测准确率未下滑的情况下,真阳性率保持不变,而假阳性率下降,模型AUC值有所提升,对违规样本预测的准确性有一定优化。其中,随机森林模型在全样本下预测准确率为99.96%,AUC为0.61;而在过采样下预测准确率为99.96%,AUC为0.68。极端梯度提升树模型在全样本下预测准确率为99.96%,AUC为0.81;而在过采样下预测准确率为99.96%,AUC保持0.81。改进的梯度提升树模型在全样本下预测准确率为99.49%,AUC为0.46;而在过采样下预测准确率为99.83%,AUC为0.63。三是支持向量机模型准确率稳定在99.96%,负面样本召回率仍为0,正面样本召回率和假阳率仍为100%,模型整体准确率未见提升。
2. 欠采样分析
本文使用随机欠采样方法(Random under Sampler)5,按照1:5比例,以负面样本数量为基准,针对正面样本进行随机抽取,重新组合训练样本,预测结果如表4所示:一是模型整体AUC较过采样有明显提高,平均AUC由过采样的0.68提升至0.81,提升幅度近20%,拟合性能进一步优化。二是准确率和正面样本召回率出现小幅下滑,但负面样本召回率明显提升,平均达到60%,假阳性则基本降至40%以下,说明更多负面样本可被预测识别出,更少负面样本被错误归类。
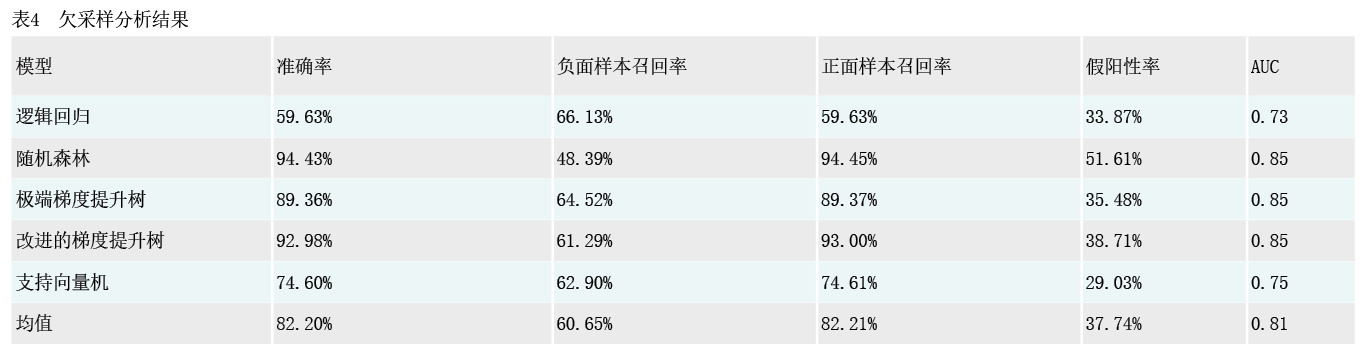
具体就每个模型而言:一是极端梯度提升树模型性能大幅提升,在小幅牺牲准确率(降至89.36%)的前提下,负面样本召回率从3.23%提升至64.52%,假阳性率从96.67%下降至35.48%,针对负面样本的预测性能明显提高,同时AUC自0.81提升至0.85,模型综合性能表现为各模型最佳。二是随机森林模型和改进的梯度提升树模型在对总体样本预测准确率小幅下降5%—7%的情况下,保持较稳定的真阳性率,而假阳性率分别下降至51.61%和38.71%,负面样本召回率分别提升至48.39%和61.29%,总体模型AUC均稳定在0.85,对违规样本的预测性能明显改善。其中,随机森林模型在过采样下预测准确率为99.96%,AUC为0.68;而在欠采样下预测准确率为94.43%,AUC为0.85。改进的梯度提升树模型在过采样下预测准确率为99.83%,AUC为0.63;而在欠采样下预测准确率为92.98%,AUC为0.85。三是支持向量机模型对违规样本预测的准确率下降近25%,下降幅度较大,而负面样本召回率提升到62.90%,AUC从过采样下的0.52提升为欠采样下的0.75,综合来说具备一定的负面样本预测能力。四是逻辑回归模型的整体准确率为59.63%,较过采样下小幅提升2%,但负面样本召回率和假阳性率与过采样下表现相同,说明欠采样方法对逻辑回归模型不具备提升效果。
总体而言,全采样、过采样、欠采样三种模式对比之下,欠采样模式下整体AUC水平最高,虽然准确率相较另外两种模式有小幅度下降,但针对负面样本的重要指标——负面样本召回率和假阳性率得到平衡。其中,极端梯度提升树模型表现最佳,整体准确率保持近90%的水平,AUC达到各模型中最高,为0.85,且负面样本召回率均接近64%,假阳性率仅35%。随机森林和改进的梯度提升树紧随其后,整体准确率和AUC与极端梯度提升树模型不相上下,但负面样本召回率较极端梯度提升树模型偏低。
(三)集成方法学习
为进一步提高模型整体性能,优化负面样本召回预测水平,在采样方法以外,本文引入集成算法(Ensemble Methods)6。为避免数据过度拟合以及解决样本不平衡问题,选取平衡装袋分类器(Balanced Bagging Classifier),允许在训练每个分类器之前对数据集的每个子集进行重新采样,从而实现数据子集的平衡。
在平衡装袋分类器技术下,基于全样本数据进行训练,所有模型预测准确率的均值为67.22%,劣于仅采用两种采样方法下模型预测效果;但是负面样本召回率达75.81%,优于仅采用采样方法的预测结果;各模型AUC均值达0.804,接近欠采样水平。相较于采样,装袋算法这一集成算法负面样本召回能力更强,但整体准确率不佳。为充分发挥二者优势,本文将两种方式进行结合。
1. 过采样下的平衡装袋分类器
本文将过采样算法和平衡装袋分类器进行结合,按照1000:1比例进行过采样,同时对逻辑回归等5种算法进行平衡分袋集成训练。结果如表5所示:一是模型整体AUC较过采样有明显提高,平均AUC从普通过采样下的0.68提升至0.81,提升幅度近20%,拟合性能进一步优化。二是准确率小幅下滑,从91.54%下降至85.74%,但负面样本召回率从15.49%提升至60.32%,假阳率从84.51%下降至39.68%,提升幅度非常明显,说明更多负面样本可被预测识别出,更少负面样本被错误归类。
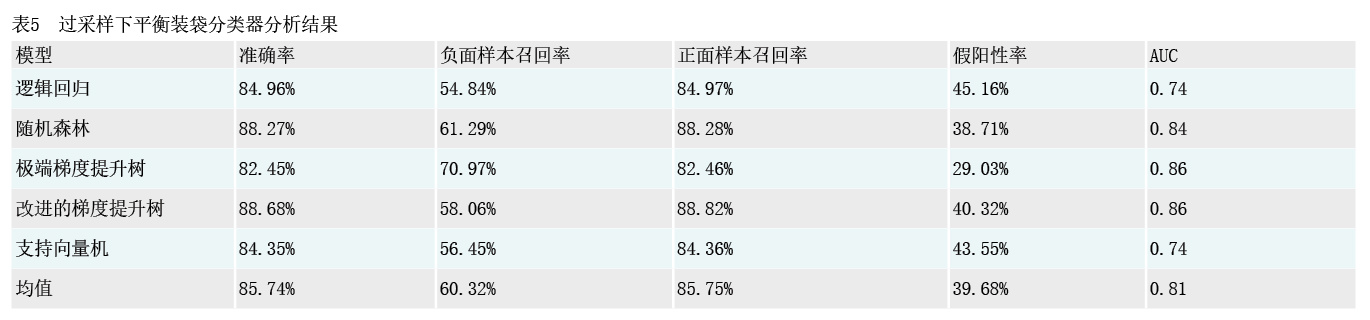
具体就每个模型而言:一是极端梯度提升树模型表现出色,总体样本准确率为82.45%,负面样本召回率为70.97%,AUC为0.86,模型综合性能表现为各模型最佳,较普通过采样模式召回率更佳。二是随机森林模型和改进的梯度提升树模型对总体样本预测准确率保持在88%以上,负面样本召回率提升至60%左右,模型AUC分别为0.84和0.86,表现较佳。三是逻辑回归和支持向量机模型的总体样本预测准确率位于84%,而负面样本召回率位于55%±1%,表现良好。
2. 欠采样下的平衡装袋分类器
本文将欠采样算法和平衡装袋分类器进行结合,对样本使用随机欠采样方法,按照1:5比例,以负面样本数量为基准针对正面样本进行随机抽取,同时对逻辑回归等5种算法进行平衡分袋集成训练,得到结果如表6所示:一是模型整体AUC的0.82与普通欠采样模式的0.81对比,提升幅度相差不大。二是模型准确率和负面样本召回率各有优劣。欠采样下的平衡装袋分类器总体样本准确率为74.77%,负面样本召回率为73.23%,而普通欠采样模式下准确率为82.20%,负面样本召回率为60.65%,总体样本准确率更高但负面样本召回能力不如前者。
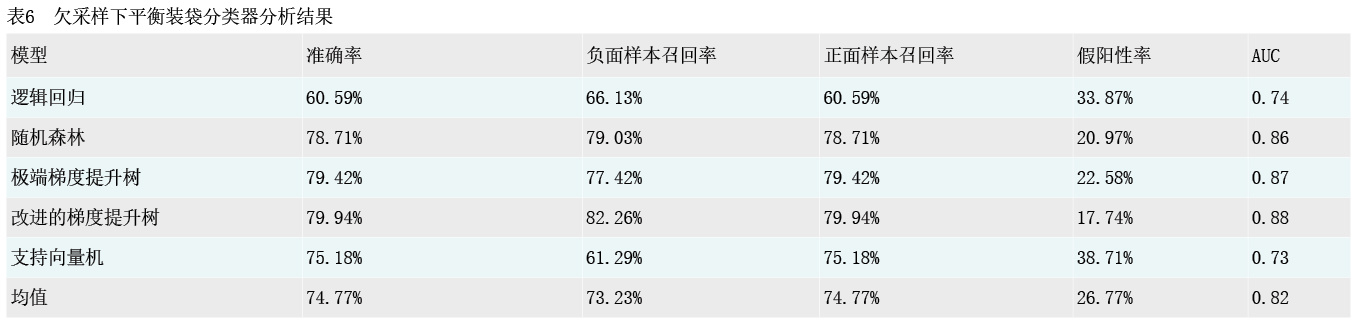
具体就每个模型而言:一是随机森林、极端梯度提升树、改进的梯度提升树模型准确率有明显下降,较普通欠采样模型的90%区间下降至78%—80%,但负面样本召回能力较强,分别为79.03%、77.42%、82.26%,负面样本预测召回能力较普通欠采样模型进一步改善。同时,AUC方面,改进的梯度提升树模型达0.88,极端梯度提升树模型达0.87,随机森林达0.86,为各模式下的最佳水平。二是逻辑回归和支持向量机模型较普通欠采样模式未见明显提升。其中,逻辑回归模型总体预测准确率为60.59%,负面样本召回率为66.13%,而支持向量机模型准确率为75.18%,负面样本召回率为61.29%。二者的重点评价指标相较普通欠采样模式差别均在1%以内。
总体来说,基于全样本分析模式对比,平衡装袋分类器对模型训练效果有大幅提升。进一步,在将采样方法和平衡装袋分类器相结合的情况下,模型结果较仅采用采样方法或平衡装袋分类器更为高效和平衡——欠采样下平衡装袋分类器和过采样下平衡装袋分类器平均AUC均高于0.80,整体表现较佳,前者倾向于拥有更高负面召回率,后者倾向拥有更高的总体样本准确率。两种模式的平衡装袋分类器下,极端梯度提升树、改进的梯度提升树、随机森林表现均位属前列。
(四)样本外检验
为评估模型效果,进一步对2021年微观主体数据进行预测。结果显示,过采样下平衡装袋分类器的平均总体预测准确率为84.51%,负面样本召回率为56.84%;欠采样下平衡装袋分类器的平均总体预测准确率为81.91%,负面样本召回率为55.09%。二者预测准确率均高于80%,对负面样本的预测召回比例均超过55%,相比较之下,过采样下平衡装袋分类器对于实际样本外数据预测结果表现更佳。其中,极端梯度提升树模型在两种模式下均较其他模型预测效果更佳,对整体样本预测准确率高达85%,对负面样本预测召回率分别为68.42%及71.93%。上述探索反映了过采样、欠采样等采样方法和平衡装袋分类器等集成学习方法可在一定程度上解决全样本不平衡问题,实现对负面主体相对稳定的预测,对外汇监管实务工作具有参考意义。
五、基于大数据和机器学习技术的外汇微观监管框架
(一)外汇微观监管的目标与原则
1. 监管目标
在外汇市场“宏观审慎+微观监管”两位一体管理框架下,顺应金融科技发展和贸易投资便利化趋势,充分利用数字技术和监管科技成果,强化数据赋能、科技赋能,探索构建“四位一体”的外汇微观监管框架,提升外汇监管有效性,维护外汇市场秩序。
2. 监管原则
基于大数据和机器学习技术的外汇微观监管框架需要遵循以下原则:一是业务全覆盖原则。在外汇微观监测预警过程中,将所有相关机构、所有涉外业务纳入监测预警范围,做到监测全覆盖,不留监管空白,实现对微观主体的全景式监测。二是有效使用原则。将前沿科技手段应用与人工监管有机结合,定期验证大数据和机器学习技术在外汇微观监管方面的使用和配置情况,不断调整机器学习技术模型,有效提高监测预警精度。三是最小干预原则。大数据和机器学习技术在提升外汇微观监管效率的同时,也可能会出现系统误判、线索不足等问题,因此在基于大数据和机器学习技术的外汇微观监管中,要尽可能少干预企业日常经营,避免给市场经营主体带来不必要的困扰。
(二)“四位一体”外汇微观监管框架
1. 数据层
搭建外汇管理大数据指标体系。一是构建以微观主体为主线的数据体系,系统整合12大类外汇业务数据,融合税务、海关等部门间的信息交换和共享数据,以及引入外部公开数据等。根据实需原则调取、追踪微观主体外汇业务数据,为运用大数据和机器学习技术进行监测预警提供完备的数据基础。二是细化外汇违法违规相关数据,通过自然语言处理等文本技术将外汇处罚决定书内容纳入数据体系,完善微观主体违法违规行为相关信息,完善“负面主体”信息库建设,并加强对该数据的应用。三是持续优化指标设置。结合外汇监管的具体场景,不断丰富模型指标,提取更多微观主体涉嫌外汇违规的敏感特征,提升模型拟合的效果。
2. 模型层
强化科技创新应用。提升外汇微观监管能力,离不开大量业务数据的输入和处理,需要不断迭代才能训练出好的模型。一是逐步由专家规则筛查转向机器自主学习、甄别和挖掘异常主体和交易特征,更深入地实践机器学习、挖掘数据资源、提高数据加工水平,充分发挥机器的智能感知功能。建立健全监测预警模型“黑箱”,在现有监测预警技术基础上,加大对大数据、机器学习、人工智能等技术的应用,丰富监测预警模型库建设。二是加大技术与外汇业务融合,紧扣外汇业务实际,丰富应用场景,调整监测预警指标体系、完善模型库建设,增强外汇监测预警模型解释力。例如,探索引入异常点监测算法、集成学习算法等,不断提高模型预测能力。三是根据监测和检查结果反向优化实证模型。加大实践检验力度,及时查找模型误判误断的原因,对模型的参数进行修正。通过反向评估各种模型的拟合情况,使系统能够利用数据总结新特征,精准识别违规行为并进行预警,提升监测预警的精准度。四是持续提高外汇领域微观主体行为监测预警平台的易用性。由于外汇领域微观主体行为监测预警模型需要熟悉编程、大数据分析等技术,存在一定的技术门槛,为便于外汇监管人员使用,应综合优化模型应用,根据优化后的模型设计自动化、可视化的监测预警平台,提升监测预警系统的用户体验。
3. 监管层
提升微观监管应用能力。尽管运用采样技术和集成学习方法可实现模型优化,整体负面样本召回率有一定上升,但距离精准、智能筛选违规主体还有差距,后续仍需进一步提升监管应用能力,才能实现对违规主体的有力打击。一是加大对监测预警系统所发现的疑似违规主体的筛查,系统研判异常主体可疑业务相关线索,并将有待进一步检查的异常主体列入关注名单。对确实存在可疑行为的主体,再开展相关检查,谨防出现因监测系统误判误断引起不当检查,给微观主体生产经营带来困扰。二是对模型拟合预测的涉嫌外汇违规的微观主体,与现有其他监测预警方法结果进行对比分析,特别关注双重命中的微观主体。充分利用各类人工智能的特征和优点,挖掘出高风险的可疑主体,集中力量对高风险主体进行分析研判。三是定期将关注名单及相关线索移交微观主体所在地外汇检查部门,对异常主体开展非现场检查。加强与反洗钱、公安、税务、海关等部门的监测成果与经验分享,对异常主体开展现场检查后应及时反馈对筛选线索的检查结果,以不断优化监测预警系统建设,提升监测预警系统监测能力。
4. 安全层
完善安全保障建设。在加大大数据和机器学习等技术应用的同时,保障外汇数据信息安全始终是底线。为此,要做到以下两点:一要强化数据安全性保障。加强外汇数据安全建设,完善数据相关内控制度建设,规范外汇数据使用规则,筑牢外汇数据安全防线。加强数据安全培训,提升监管人员安全意识,严格做到“内外有别”。二要强化系统稳健性保障。及时通过机器深度学习及时查找和修订大数据功能模块中可能存在的系统设计漏洞、软件缺陷、程序运行问题等计算机层面风险。建立健全应急预案,有效应对大数据技术应用过程中可能出现的突发性障碍,确保大数据分析在外汇管理中应用的安全性,降低外汇管理风险。
六、结论与政策建议
本文研究发现:一是通过叠加使用SMOTE等采样算法和平衡装袋分类器等集成算法可有效强化模型预测效果,平均AUC值稳定在0.81以上,较不使用上述算法或采用单一算法预测效果有明显提升。二是在多种机器学习技术中,极端梯度提升树、改进的梯度提升树、随机森林三项模型可实现较佳预测效果,整体准确率保持在80%以上。三是搭建模型可实现对外汇领域微观主体监测的稳定预警效果。通过样本外检验发现,模型样本外预测的准确率最高可达85%,70%以上负面样本可以被成功预测挖掘。基于此,本文有如下政策建议:
一是依托各数据研判中心,进一步完善微观主体信息库建设并强化利用,为全方位描绘负面主体特征提供基础,助力提高模型预测的精准度。二是完善监管数据指标体系建设,推进外汇、商务、税务、海关等业务数据信息的综合利用,支持开展多维数据分析;积极探索与其他监管机构共享负面主体信息的长效机制,消除部门间“信息孤岛”;加强涉汇信息及线索共享研判,提高跨部门联合监管能力。三是加强利用基于大数据和机器学习技术的监管平台和工具,充分挖掘数据资源价值,完善分析模型和指标体系,持续提升对外汇违法违规行为的筛查能力。持续加强监管平台人机交互水平建设,设计自动化、可视化的交互界面,提高外汇监管平台和工具的易用性。同时,提高模型筛查线索能力,促进系统自主迭代升级,实现违规行为精准识别或预警。
参考文献
[1] 翟伟丽. 大数据时代的金融体系重构与资本市场变革[J]. 证券市场导报,2014(02):47-50.
[2] 阮健弘. 大数据技术提升金融统计分析能力[J]. 中国金融,2022(02):14-16.
[3] 蒋锋,张文雅. 机器学习方法在经济研究中的应用[J]. 统计与决策,2022,38(04):43-49.
[4] 王达,周映雪. 随机森林模型在宏观审慎监管中的应用——基于18个国家数据的实证研究[J]. 国际金融研究,2020(11):45-54.
[5] 王克达. 金融危机预警模型与先导指标选择[J]. 金融监管研究,2019(08):84-100.
[6] Suss J,Treitel H. Predicting Bank Distress in the UK with Machine Learning[R]. Bank of England Staff Working Paper,2019,No. 831.
[7] Samitas A,Kampourisb E,Kenourgios D. Machine Learning as an Early Warning System to Predict Financial Crisis[J]. International Review of Financial Analysis,2020,71.
1 过采样(SMOTE)方法由Nitesh V. Chawla等人于2002年首次提出,是一种基于原数据间关系生成新样本、补充原样本集的方法。该方法以负面样本点的若干个最近邻样本点为依据,随机选择N个邻近点进行差值乘上一个[0,1]范围的阈值,从而达到合成数据的目的。
2 AUC即ROC曲线(Receiver Operating Characteristic Curve)下的面积,反映模型分类器阈值不断调整的情况下的整体性能表现,提供分类算法效果的可视化结果。一般而言,AUC等于1,表明分类器效果完美;AUC处于[0.5,1]区间,表明优于随机分类器,且数值越大,分类器效果越好。
3 通常而言,正面样本与负面样本比例明显大于1:1则可被称为样本不平衡。
4 采样算法通过随机抽样放大和缩小样本数据量使样本数据分布趋于平衡,是当前机器学习研究领域中解决全样本数据不平衡问题的主流方法之一。采样主要分为欠采样和过采样,其中欠采样指压缩占比大的类别样本数据量,过采样指扩大占比小的类别样本数据量,二者目的均为使样本比例更为均衡。
5 随机欠采样是一种非启发式采样方法,主要目的是通过随机抽选,降低多数类样本集数据数量,实现对整体样本集的数据平衡。
6 集成算法通过组合多个弱监督模型强化训练,从而获得一个更全面的强监督模型。
课题主持人:郭云喜;课题组成员:张志东、徐宏练、李继伟、陈树生、翟宗辉、蒋涛、叶维皓、周碧莹、徐亮、江丽媛
本文不代表作者所在单位观点,也不反映《中国外汇》杂志编辑部观点。

